
Dr. Iain Stitt
Data Scientist and Neuroscientist
Insight project
Through September and October 2017 I participated in the Insight Data Science Fellows program in New York City. Insight is a program that helps people transition from academia to careers in the data science industry. One of the cornerstones of the program is the Insight Data Science project, a 3 week endeavor completed using Python machine learning libraries and SQL. Below, you can find a blog post I wrote to summarize my Insight project entitled “Indie game intuition”.
The code for this project can be found on my Github page here: https://github.com/iainstitt/Indie-Game-Intuition
Indie Game Intuition
Project subheader: Segment the Steam market to predict which users will buy games under development.
Background:
The PC gaming industry has been steadily growing for the last decade, and is projected to continue to grow in the coming years. To illustrate just how big the PC market is today, PC gaming revenue reached $36B USD during 2016, a value just shy of global movie box office sales from the same time period.
One of the driving forces behind the growth of PC gaming has been an influx of various indie game developer studios, who produce highly innovative games that are tailored to specific niche segments of the PC gaming market. One great example is a game called Rimworld, an aesthetically retro-style colonization game thats main draw is an intelligent AI system that generates unique and captivating story lines (screenshot right).
The indie game Rimworld:

Problem description:
Making games costs money. So much so in fact that the budgets of some big ticket games can stretch into the hundreds of millions of dollars (just look at the Call of Duty franchise from Activision as an example). Although budgets for indie games tend to be orders of magnitude lower, producing a new game can represent a significant financial risk for indie game studios.
Although indie developers have a reasonable ‘gut feeling’ of how their target users will be engaged by games already during the ideation and early development stages, they currently do not have a quantitative approach to back those feelings up. A miscalculation in terms of how the PC gaming market will respond to a new game may lead to a loss in revenue: a situation that may prove catastrophic for many indie game development studios.
The goal of this work was to build a tool for game developers to help them understand the segmentation of the PC gaming market, and predict which users are most likely to purchase games they are currently developing. If implemented early in game development stages, developers could use this tool to tweak the characteristics of their game to either optimize the engagement of their target users, or maximize revenue through increased sales.
The dataset:
Steam is the largest and most widely recognized platform for PC gaming, with an estimated 125 million currently active users. For those unfamiliar with PC gaming, the Steam platform is akin to the Google Play or Apple App stores for PC gaming. In addition to facilitating game purchases, Steam also has a very strong community, allowing users to connect with friends and play games together online.
If you know a users unique steam ID, it's possible to query detailed information about them through the Steam Web API. However, I could find no publicly available list of Steam user ID’s to work with. To compile my own list of Steam user ID’s I decided to employ a network search approach, where I started with a set of randomly selected ‘root users’, and used the Steam Web API to query a list of their friends steam ID’s, then repeated the process for their friend’s friends. This network search process is illustrated in the figure to the right:

Using a set of 30 root users and a two stage network search approach (i.e, stopping at second degree friends), I was able to compile a list of 550,000 unique Steam ID’s. Now that I had a list of users, I could use the Steam Web API to query detailed information about each user, such as what games they own, how much time they spend playing each game, how many Steam friends they have, which country they are from, etc. Similarly, I used a combination of the Steam Web API and scraping the Steam webstore to gather detailed information about 20,000 Steam games, including game genre, game description, hardware requirements, and developer studio.
Although the typical Steam user tended to own a lot of games (130 on average!), I wanted to gain some intuition about how much time they actually spend playing each of these games. To visualize how users play games, I generated a table where each row is an individual user, each column is a particular game, and the color of each entry denotes the amount of time users have spent playing each game.

As you can see above, this matrix is generally quite sparse with the exception of a few ‘vertical stripes’, indicating that many users spend a lot of their time playing just a handful of games. The most salient vertical stripe (marked with *) actually corresponds to Counter Strike: Global Offensive, one of the most popular games of the last several years. In addition, there are a few ‘horizontal stripes’ in the above plot, indicating that certain users that tend to play a lot of different games. While this plot does provide some information about Steam user behavior, it is generally quite hard to interpret in this form.
To break down information about how Steam users play games into a more interpretable form, I employed a non-linear dimensionality reduction technique called t-distributed stochastic neighbor embedding (t-SNE). What this technique does is project very high dimensional data (> 700 games in this case) into just two dimensions by matching the probability distributions of distances between data points (users in this case) from the high-dimensional space to the low-dimensional space. To explain this method more intuitively given the example above, users that play a similar combination of games are located close by in the high-dimensional ‘game’ space, and will therefore be embedded into a similar region of the low-dimensional 'market' space. Similarly, if users play completely different games they will be very distant in the high-dimensional space, and will thus be projected into distant regions of the low-dimensional space. The animation below illustrates how this algorithm works iteratively to segment the Steam market based on user behavior:
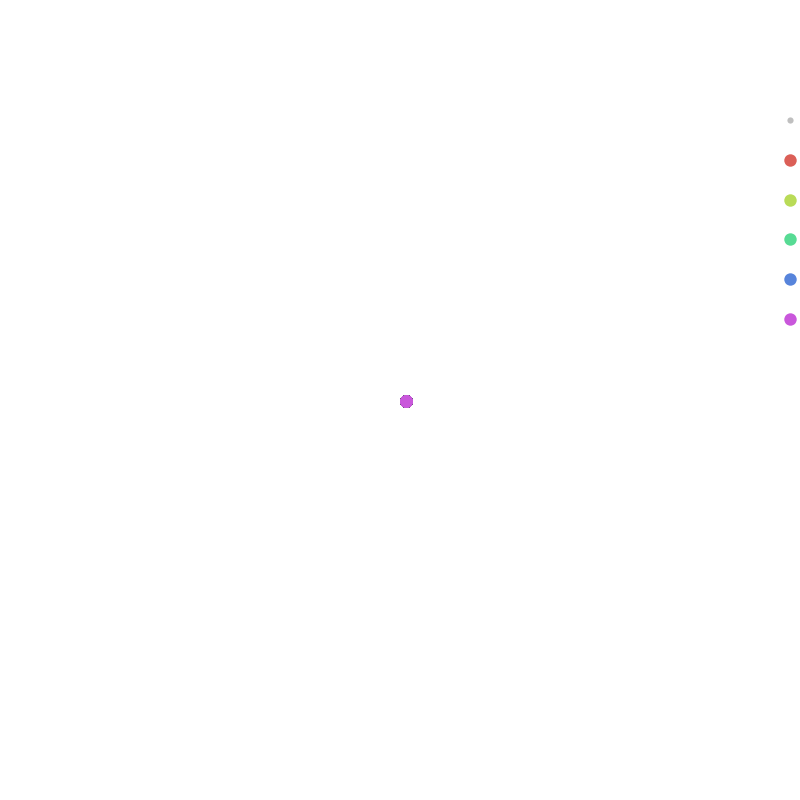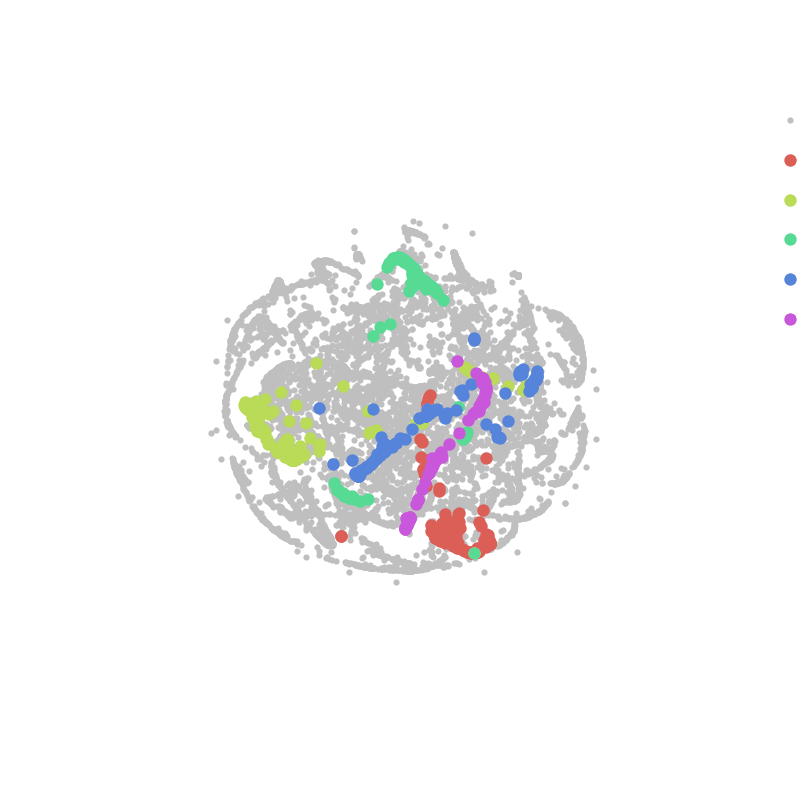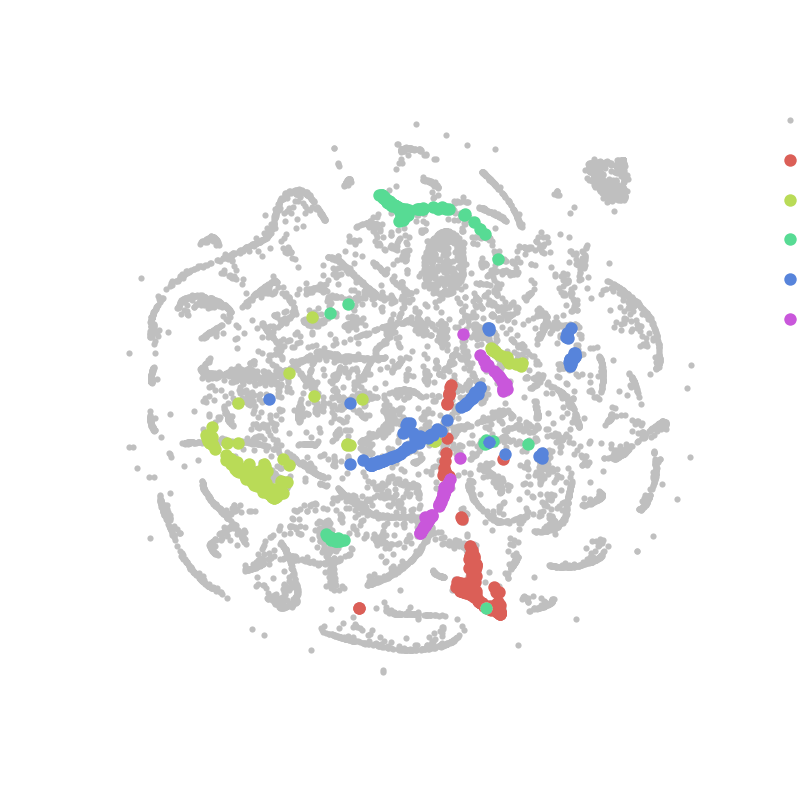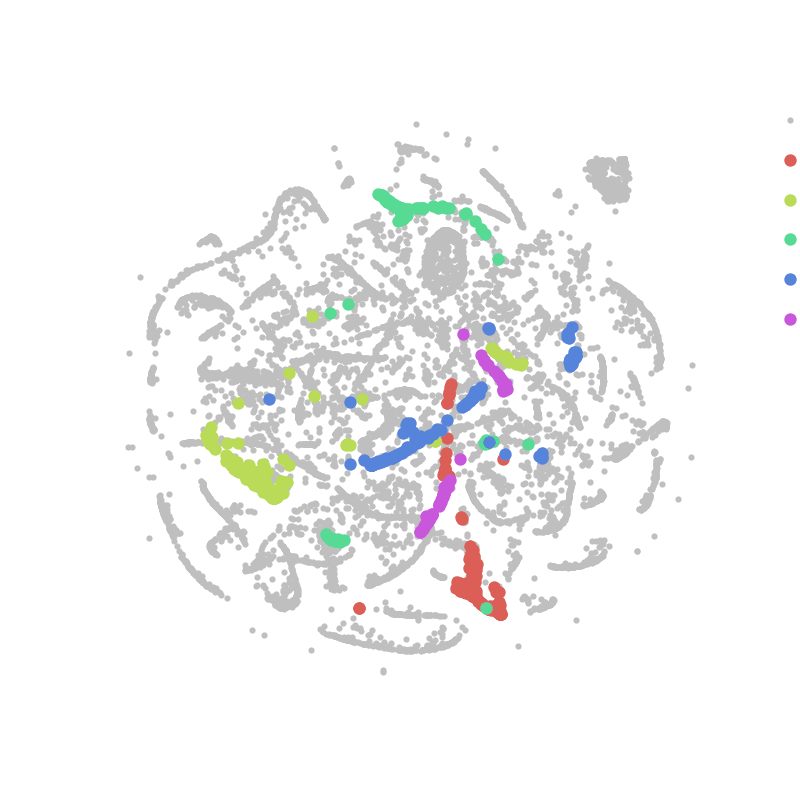

Steam users favorite game:
As can be seen above, the t-SNE algorithm clusters users together that have similar behavior (or favorite games), producing a visualization that game developers can use to better understand the segmentation of the Steam PC gaming market. When coupled with a predictive model for game sales resolved for each user, this visualization can provide indie game developers insight about how their games will penetrate the PC gaming market.
Feature engineering:
To accurately predict if a user will purchase a game, we need to understand the types of games individual users like to play, and engineer a metric that captures the similarity games users own to those developers are working on. I thought quite a bit about how best to tackle this problem given the information at my disposal, and settled on computing the term-frequency inverse document frequency (tf-idf) cosine similarity between the tags and description of the game on offer, and the games that each user currently owns. In simple terms, what this algorithm does is it quantifies the similarity of word representations between documents. For example, if one game description includes “Mars based shooter where you take on an alliance of aliens and evil robots” and another reads “Defend Earth from invading aliens”, these two descriptions will have a non-zero similarity score since both descriptions contain the word ‘aliens’.
The model:
To predict if users will purchase games that are yet to be released, I reasoned that the best approach would be to train a model on past user purchases. At its core, this is a binary classification problem, where we want to predict if users will own certain games based off user and game features, as well as the user/game tf-idf similarity metric outlined above.
Since I was dealing with a mixture of numeric (# of friends, game price, Metacritic score, etc) and categorical features (game genre, developer, country of origin, etc) I needed to select a model that could robustly handle input data of varying scales. Therefore, I decided to employ a random forest model due to their well-known insensitivity to the scale of inputs and interpretability.
Given that most Steam users do not own most of the games available on Steam, I was dealing with a pretty severe class imbalance problem (20 to 1). To deal with this imbalance, I randomly undersampled the majority class, which in this case were user-game combinations where the user did not own the game. Finally, to avoid overfitting the model to the class balanced data, I randomly segmented data into 10 smaller blocks, and trained random forest models on each separate block. The logic behind this approach is that while individual models may overfit data in each small segment, the aggregated predictions of all random forest models will be more robust to overfitting since each model was trained on different segments of the data.


In these models, the most important features for determining if users own certain games were the number of recommendations the game received on the Steam community platform, and the developer studio that produced the game. As an aside, digging a bit deeper into the developer importance I found that a great deal of the predictive effect of this feature was explained by a single game developer studio: Valve, the producers of Half-Life and Counter Strike games and owners of the Steam platform.
To quantify how well my ensemble of random forest models can predict which games users own, I tested model performance on a hold-out dataset that contained the original 20 to 1 class imbalance. As can be seen from the confusion matrix above, the ensemble of random forest classifiers performed reasonably well at correctly predicting if users owned games or not, with a recall of 0.81.
Business use case:
To illustrate how t-SNE market segmentation and predictive modeling can be used in practice, I am going to walk you through how a game developer might deploy this tool to make quantitatively driven business decisions, and understand which Steam users will buy games they have under development.
SCS Software is a game development studio based in the Czech Republic that have produced a series of truck and bus driving simulation games over the last decade. One of the latest iterations of these games was entitled “Euro Truck Simulator 2”, where as the title suggests, you drive around Europe in a truck picking up cargo and delivering it to defined locations. Below you can see a gif of actual gameplay from Euro Truck Simulator 2:

In the hypothetical scenario that SCS software was working on producing a third installment in their Euro Truck series (i.e, “Euro Truck Simulator 3”), natural questions that arise may include: how much should we price this game to maximize revenue? And, what kind of user will likely buy this game?
To answer these questions I generated a set of hypothetical features for a “Euro Truck Simulator 3” title and fed them into the ensemble of random forest models, with the aim of trying to determine the optimal price for the game to maximize revenue. The rationale behind this approach is that while more users may indeed buy the game if it is cheaper, less revenue will flow to the developers per game sale because of the reduced price. Likewise, if the price for the game is too high, fewer people will buy the game, also resulting in reduced revenue. In the figure to the right you can see both the predicted sales and extrapolated revenue for “Euro Truck Simulator 3” where I have kept all features constant, except for game price, which varied between $5 and $30.



As you can see, if the game developers are aiming to maximize their revenue, then the model suggests that they should price the new game at $15, despite them being projected to sell more games when it is priced at $10.
Now that we have a prediction of which users are more likely to buy the new “Euro Truck Simulator 3” game, we can project these results into the t-SNE space to understand which segments of the Steam market will be engaged by this game. While the predicted market penetration of "Euro Truck Simulator 3" appears broad, there are indeed a few concentrated segments of the market that are predicted to be more receptive to this game. SCS software could use this information to specifically target these users with advertisements for the game as it approaches the release date.
For one last sanity check, I decided to perform the same experiment with a more widely anticipated game: Half-Life 3. To say that Half-Life 3 is hyped is an understatement: over the last decade there have been countless rumors, leaks, false starts, and let downs for fans of the Half-Life series, with still no game to speak of. To see how a theoretical Half-Life 3 title would fare in the Steam market, I fed in some hypothetical features for the game into the model (actually, I lifted the game description from Marc Laidlaws recent blog post). In contrast to Euro Truck Simulator 3, which had projected sales of ~0.3% of the Steam market, a new Half-Life 3 title is projected to be purchased by approximately 80% of Steam users. Below you can see the breakdown of the probability users will by each game:

Given that there are an estimated 125 million active users on the Steam platform, a new Half-Life title would be projected to reap hundreds of millions of dollars in game sales. So, Valve…. hurry up and make Half-Life 3 already!
In this blog post I have walked you through how I generated a market segmentation visualization and predictive analytics tool that can help game developers understand their penetration of the Steam PC gaming market. Although the use case I outlined above was geared toward optimizing revenue through modifying game price, game developers could also use this tool to receive quantitative feedback for tweaking actual game characteristics (eg, first person versus third person shooter).